Understanding dictionary-based text analytics in deriving insights from freeform comments
Blue introduces Text Analytics, a powerful new feature that unlocks the wealth of data present in freeform comments.
In a nutshell, Blue’s Text Analytics engine uses powerful algorithms that examine the content of freeform comments provided by raters and based upon the assigned dictionary it attempts to place the comments into predefined themes established in the dictionary. For more information, take a look at the Dictionaries.
Freeform comments contain valuable information that is difficult to find elsewhere. The challenge comes in quickly analyzing and quantifying the large amount of freeform feedback that may be received from a single project.
In the past, any analysis of freeform comments was typically restricted to individual instructors who would read, interpret and act on any findings. Due to cost and complexity of conducting a manual analysis at a department or school wide level, administrators typically had no access to this valuable source of feedback. Only with the advent of inexpensive computing and the more recent advancement in text mining has this data started to unlock its hidden value.
For a quick overview in understanding the capabilities of Blue Text Analytics, read the whitepaper released by Explorance.
Flexible Spelling
A quirk of English in particular is the rather flexible spelling often encountered. There are some well-known cultural variations in spelling. Americans generally drop the letter u from words like color/colour and humor/humour while the British prefer s to z in many cases like recognise/recognize and organise/organize. However, the well known semi-official culturally unique spellings are nothing compared to the creative misspelling of words that still manage to convey their message. During analysis of 1.8 million sample comments, 61 different ways of spelling enthusiastic were discovered. Text Analytics is able to correctly process many cultural variations in spelling as well as commonly used incorrect spellings.
Regional Word Choice
English is always changing and adapting to it's surroundings. Age, level of education, context, geographic region and more can all play a part in word choice and meanings. During the development of Text Analytics, the cultural differences between English speakers around the globe became a significant challenge. Not only was slang encountered that varied from region to region, but unexpected differences in word choice between cultures also cropped up. Some well known examples include, elevator(USA) and lift(UK) or truck(USA) and lorry(UK). A few domain specific examples are more relevant, for example, what a North American refers to as a course, New Zealanders refer to as a paper, while in the USA a dean is usually the top administrative official in a university whereas in the UK and Canada a dean refers to the head of an academic department. Where possible attempts were made to take regional differences into consideration but it's a challenge. For example, the word 'mark' when found alone is ignored assumed to be a name, but when 'mark' is found after the words high, low, etc it is considered an evaluation result. Currently the best solution to handle regional differences in language is to create region specific dictionaries, but since words often carry more than one meaning, as in the case of "paper", the likelihood of false positives is still high.
Context Affects Meaning
Regional word choice and flexible spelling pose significant challenges, but the flexible nature of English makes an already challenging computer problem even more difficult. Context plays such a key role in the meaning of a word or phrase, for instance, to agree with someone about something very obvious we might say "of course", but a less sophisticated software tool may recognize the word "course" and think the comment is referring to a class. Another example, "He's not a good teacher, he's great.", can easily be mistaken from a computers perspective as "not good" or "bad", but clearly that's not the intended meaning. The To_be_Ignored category in the BTA Teaching and Learning Dictionary was created specifically to identify and remove words like "of course" in an effort to reduce false positives. In addition, the Text Analytics engine performs sentiment analysis in an attempt to interpret the true meaning of a comment.
People versus Blue Text Analytics
Ultimately, a qualified flesh and blood person, given enough time, tasked with reviewing freeform comments will always produce better results than even the most powerful computers. On the other hand, computers can process tens of thousands of comments in mere moments with a high enough degree of accuracy to be valuable. During the construction and subsequent validation of the BTA Teaching and Learning Dictionary, we were able to achieve 80% precision with over 90% coverage using a specific set of questions and a random sample of feedback. There are definitely trade-offs, potentially weeks of painstaking and expensive analysis to produce highly accurate results versus a few minutes of readily available computing processing to produce fairly accurate results.
Volume of Comments
The value of Text Analytics is particularly noticeable when analyzing hundreds or thousands of comments. In fact, the larger the data set the better. Comment length also plays a factor in the accuracy of the results. All freeform comments have value within Text Analytics, but long descriptive comments have much more potential to be unlocked with Text Analytics then one or two word comments. With large data sets of long descriptive comments, Text Analytics is able to uncover trends and identify areas primed for further inquiry that otherwise would be too resource intensive to discover manually.
Use Text Analytics when there are too many comments to reasonably read and analyze manually.
Coverage
An important concept to understand in Text Analytics is the idea of coverage. This refers to the percentage of processed comments that were assigned to at least one theme. The higher the coverage the more comments will appear in the results and the more likely it is that the true sentiments of the raters are being assessed.
Coverage is highly dependent on the question being asked and how it is asked. Coverage on an individual question for an individual course isn't likely to provide much insight, rather the insights will come by analyzing large data sets and attempting to discern the cause of any deviation from the mean. Blue Text Analytics uses a dictionary-based text analytics approach. As observed in various research studies including Grimmer and Stewart (2013), it is important to apply the BTA Teaching and Learning Dictionary to "Understanding Dictionary-based Text Analytics in Deriving Insights from Freeform Comments".
“For dictionary methods to work well, the scores attached to words must closely align with how the words are used in a particular context. If a dictionary is developed for a specific application, then this assumption should be easy to justify. But when dictionaries are created in one substantive area and then applied to another problems, serious errors can occur. Perhaps the clearest example of this is shown in Loughran and McDonald (2011).”
- Grimmer, Justin, and Brandon M. Stewart. "Text as data: The promise and pitfalls of automatic content analysis methods for political texts." Political analysis 21.3 (2013): 267-297 (PDF)
- Loughran, Tim, and Bill McDonald. "When is a liability not a liability? Textual analysis, dictionaries, and 10‐Ks." The Journal of Finance 66.1 (2011): 35-65.
With extensive testing on 1.8 million comments, the BTA Teaching and Learning Dictionary was developed to exceed a coverage rate of over 90%.
Accuracy
Being able to analyze thousands of comments in only a moment is incredibly valuable, but only if that analysis provides accurate results. To build the BTA Teaching and Learning Dictionary, we sampled comments from end of course evaluations and processed them through Blue Text Analytics then manually analyzed them and made adjustments until the accuracy of each theme met our goals.
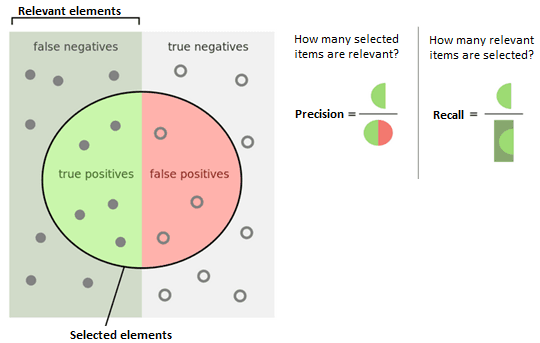
Accuracy is defined along two dimensions - precision and recall (also known as sensitivity). Precision is a percentage that refers to how often a comment that has been assigned to a theme has been correctly assigned to that theme (true positives) versus any comments that were assigned to a theme in error (false positives). Recall, refers to the fraction of the true positives that have been categorized over the total number of all existing positives in the comments. For example, suppose a computer program for recognizing cows in photographs identifies 8 cows in a picture containing 12 cows and some pigs. Of the 8 identified as cows, 5 actually are cows (true positives), while the rest are pigs (false positives). The program's precision is 5/8 while its recall is 5/12 (see Figure 1: Precision and Recall Sensitivity below). Based upon our testing, we strove to maintain a precision of at least 80%.
It is possible to increase the precision, however, there is a tendency that the higher precision, the lower the recall. In other words there is an inverse relationship between precision and recall. We maintained precision at the 80% level to balance the sensitivity (reduce the chance of missing positives, i.e., false negatives). The figure below demonstrates the relationship between precision and recall/sensitivity. The following resources provide further insight into accuracy, precision, and recall:
- Miner, Gary, John Elder IV, and Thomas Hill. Practical text mining and statistical analysis for non-structured text data applications. Academic Press, 2012.
- Aggarwal, Charu C., and ChengXiang Zhai, eds. Mining text data. Springer Science & Business Media, 2012.
- Sensitivity and Specificity
To calculate the precision rate of the result of applying the BTA Teaching and Learning Dictionary to a particular set of comments in response to a "suitable question":
- Export responses for a course feedback project.
- Select approximately 200 comments randomly from feedback on at least two questions.
- For each comment, manually assess if the comment is assigned to the correct theme or not (identify true positives and false positives).
- Calculate the precision rate and the recall rate to determine the accuracy level.
- In the event that you have identified false positives or false negatives, feel free to let us know below in the comments. Your contributions will help us continually improve the accuracy of the BTA Teaching and Learning Dictionary.